Home /
Expert Answers /
Computer Science /
consider-the-small-mdp-shown-in-figure-2-there-are-two-possible-states-s-1-and-s-2-and-two-po-pa283
(Solved): Consider the small MDP shown in Figure 2. There are two possible states, s_(1) and s_(2), and two po ...
Consider the small MDP shown in Figure 2. There are two possible states, s_(1) and s_(2), and two possible actions, a_(1) and a_(2). Rewards for each state are as shown. Each transition is labeled with its probability when a given action is taken. These probabilities are also shown in the three transition tables on the right, with rows corresponding to old state and columns corresponding to new state: i.e., (P_(a_(k)))_(i,j)= P{S_(t+1)=s_(j)?S_(i)=s_(i),A_(t)=a_(k)}. Look up the discount factor gamma assigned to your NetID in discount factor =0.7 Assuming the optimal policy is used after the current time-step, what are the four numerical values of the Q-function, Q^(**)(s,a), for each s in{s_(1),s_(2)} and a in{a_(1),a_(2)} ?
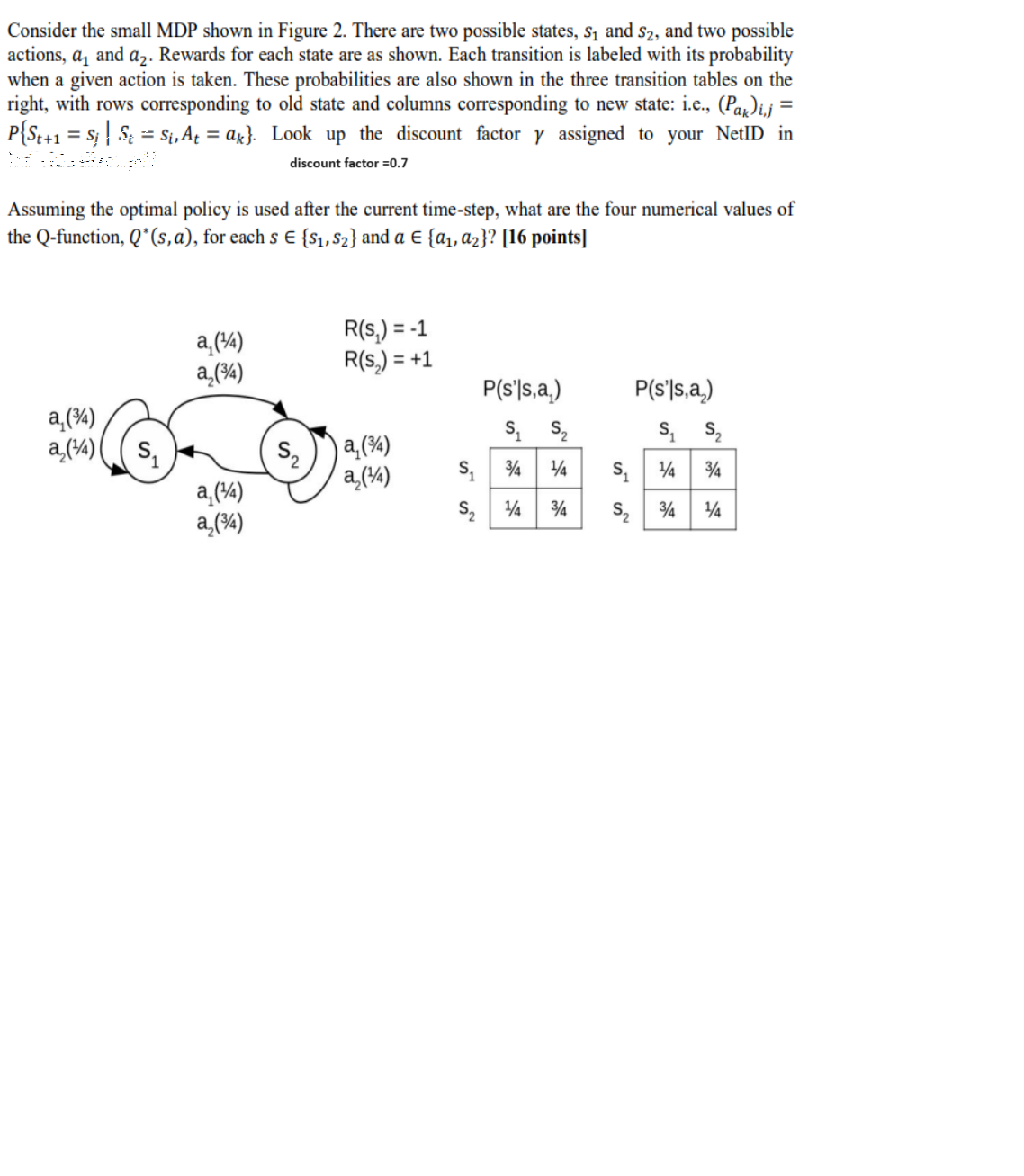
Consider the small MDP shown in Figure 2. There are two possible states, and , and two possible actions, and . Rewards for each state are as shown. Each transition is labeled with its probability when a given action is taken. These probabilities are also shown in the three transition tables on the right, with rows corresponding to old state and columns corresponding to new state: i.e., . Look up the discount factor assigned to your NetID in discount factor Assuming the optimal policy is used after the current time-step, what are the four numerical values of the Q-function, , for each and ? [16 points]